Deploying complex apps to AWS with Terraform, Ansible, and Packer
By in DevOps on Sat 11 January 2020
Recently we helped a client migrate a set of complex Ruby on Rails applications to AWS, deploying across multiple environments and regions.
They have a half-dozen SaaS products which they have built over the last decade. They had been running them on a set of shared physical servers, with lots of weird undocumented relationships between components.
There were problems with reliability and performance, as well as overall complexity. They were deploying using Capistrano to push releases directly to the production servers, so they didn't have an enforced release process between dev, staging and production environments.
The big driver for improvement, however, was the need to separate customer data by country/region. GDPR compliance is easier if they keep European data hosted in Europe. Customers in China were also complaining about poor network performance crossing the "Great Firewall".
They needed multiple environments for each app: dev, staging, production in US/Canada/EU/China, plus a "demo" environment where customers can try out the app in a sandbox.
They needed a controlled release process with automated tests and ability to roll back in case of problems. They had heavy load during certain parts of the year, and underutilization the rest of the time, so they needed autoscaling. They needed robust monitoring, metrics and alerting.
The solution
They had tried to containerize their apps, but after months of poor progress, they gave up. It was too disruptive to their development team. They had to make a lot of changes at once, and everyone was having to become deployment experts. We came in and designed a new system which required minimum changes to their apps and workflow while solving their deployment issues.
One of the most important design considerations was handling all their apps and environments with a common framework. If there are too many special cases, the system becomes unmanageable. It's a false economy to optimize one environment with custom code, but increase the cost of managing the overall system. It is better to have a standard template with configuration options. On the other hand, we can't have too much configurability, it must be "opinionated".
The apps are all similar, following the standard structure for large Rails apps: front end web, background job processing, Redis or Memcached for caching, Elasticsearch, MySQL or PostgreSQL. They need to run slightly differently in dev, staging, demo and multiple production environments. AWS China in particular has many differences from standard AWS due to missing services and lack of encryption.
They needed an automated CI/CD pipeline, running unit tests before release, standard deployment and rollback, production monitoring and centralized logging.
With a good pipeline, developers mostly don't care about deploy time, it happens in the background. Time to get a change deployed can become very important, however, when dealing with production problems. If each iteration takes a half hour to deploy, you are going to make a bad day even worse.
Running in China, with a very slow connection to the outside world, means that we have to cache things like gems and OS packages locally, rather than downloading them every time from the network. Otherwise it can take ages to build an AMI.
Architecture
Multiple AWS accounts
Running multiple apps in the same environment requires additional layers of abstraction and configuration in your automation, making things more complex.
AWS accounts are free, so we use AWS Organizations to set up a master AWS account for billing, then an AWS account per environment (dev, staging, prod). Next we create a VPC per app in each environment. That removes layers, making the deployment scripts simple and consistent between the different environments.
If we have the same ops team handling prod for multiple apps, then we can
put all the prod VPCs in the same AWS account. For extra security, we can
easily make a separate AWS account per app + environment. The scripts stay the
same, we just change the AWS_PROFILE to point to the right place.
Sharing resources between accounts
The downside to having multiple AWS accounts is that we need permissions to share resources across accounts. While we can do this with IAM, it may be better to duplicate work to improve security, reduce coupling, and keep the configuration consistent.
For example, if we are managing the DNS domain for the app in Route53 in the
prod account, then scripts in dev need cross-account permissions to create host
entries. Instead, we can use a different domain per environment, e.g.
example.com for production, example-dev.com for development. This is more
secure and keeps mistakes from affecting production. It also makes it easy to
use consistent subdomains for e.g. api.example.com or per-customer
subdomains.
Similarly, we could build an AMI in one environment and use it everywhere, but it may be better to just build it once per env. There are definitely good reasons for having immutable artifacts, running exactly the same AMI in QA and prod, but saving resources is not the main motivation.
Structure
Following is a standard AWS structure:
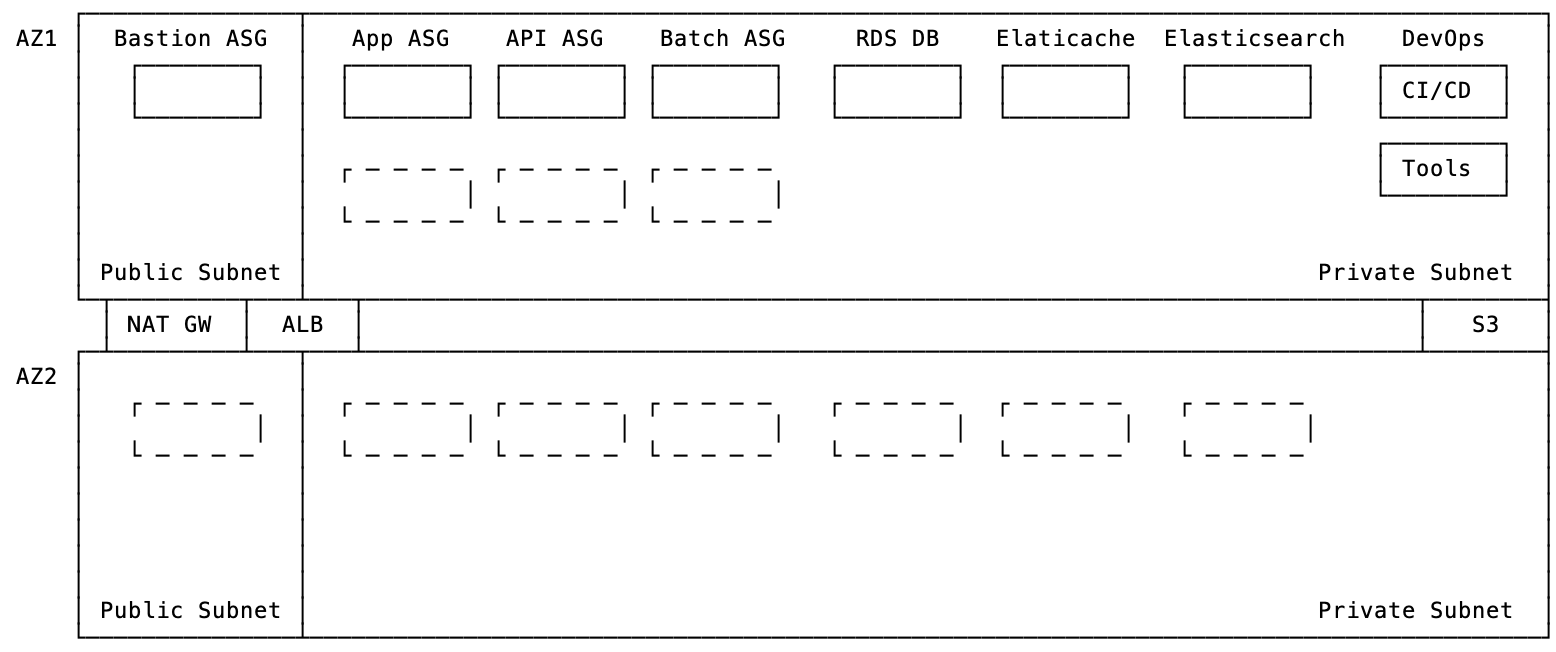
The app runs in a Virtual Private Cloud (VPC) across multiple Availability Zones (AZs) for high availability. The VPC is split into two networks, public and private.
All the data is in the private network, with controlled access. All traffic from the outside world goes through the Application Load Balancer (ALB), which proxies HTTP requests to the application instances.
The app runs in an Auto Scaling Group (ASG), which dynamically changes the number of running instances according to load. It also easily ensures high availability, because it will automatically start instances in different data centers (AZs) in case of problems.
We use the AWS Relational Database Service (RDS) service for the database, which handles high availability across multiple AZs. Similarly, we can use Elasticsearch for full text search and Elasticache for caching. Simple Storage Service (S3) stores application file data.
Bastion hosts allow users to remotely access instances in the private subnet. Users connect via ssh to the bastion, which forwards the connection to back end servers. This function can now be handled better by Amazon's new AWS Systems Manager Session Manager service.
Similarly, the NAT GW allows application servers in the private network to connect to services on the public network, e.g. partner APIs.
DevOps servers are EC2 instances used for deployment and management functions within the VPC, e.g. running Jenkins CI or ops tools like Ansible. In this case, we used the DevOps server to help ease the transition to the cloud, handling deployment processes. As we automated the application deployment, we switched to AWS CodeBuild.
Meeting legacy apps half way
Ideally, modern cloud applications do not store data on the app server. They keep all application data in a separate shared location, either RDS database or S3 file store. This allows us to automatically start and stop multiple instances according to load or as part of the deployment process.
Making complex legacy apps do this can be a lot of work, though. For this client, we used EFS to allow apps to share temporary files between servers. One server can write a file and another server can read it back on a subsequent request. This allows the application to use temp files as if it was only running on one server, without needing to make user sessions "sticky" to one server.
Deploying with CodeDeploy and Capistrano
The client originally deployed using Capistrano, pushing code directly to production systems via ssh. That doesn't work when there are multiple servers in an ASG, though, as we would need to push to all of them. It's also fragile and uncoordinated, so we risk having the system in an inconsistent state during a deploy or rollback.
The continuous integration / continuous deployment (CI/CD) system automates the process of building and deploying code. It watches the code repository for changes, runs tests, builds releases and automatically deploys them to production. It monitors the success of the deployment, rolling it back in case of problems.
In this case, just getting the app building in CI/CD was a big task, so we
first implemented a hybrid system. Developers continued to use Capistrano to
deploy the app using cap deploy. Instead of deploying directly to the prod
server, however, they pushed code to a DevOps server. At the last step, custom
rake tasks packaged the code and turned it into a
CodeDeploy release, which we deployed
into production.
Blue / Green deployment makes systems more reliable by taking advantage of how easy it is to start temporary servers in the cloud. Instead of updating code on existing servers, we can start new servers and deploy new code to them. Once we are sure it works, we switch traffic to the new servers and shut down the old ones.
Encryption
Applications with sensitive user data such as health care and financial services require high security, and encryption has become a baseline requirement for all applications. In this design, we used encryption everywhere: all data at rest is encrypted, and all data in transit is encrypted. That means turning on encryption for S3, RDS and EBS disk volumes, and using SSL on the ALB for external traffic, between the ALB and the app, and between the app and RDS and Elasticsearch.
Show me the code!
Here is a complete example of deploying an app to AWS.
It supports multiple components, e.g. web front end, background job handler, periodic jobs, a separate server to handle API traffic or web sockets connections. It uses RDS for database, Redis or Memcached, Elasticsearch, CDN for static assets, SSL, S3 buckets, encryption.
The app can run in an autoscaling group and use a CI/CD pipeline to handle blue/green deployment. It supports multiple environments: dev, staging, prod, demo, with slight differences for each.
It's built in in a modular way using Terraform, Ansible and Packer. We have used it to deploy multiple complex apps, so it handles many things that you will need, but it's also flexible enough to be tweaked when necessary for special requirements. It represents months of work.
These modules cover the following scenarios:
Minimal EC2 + RDS
- VPC with public, private and database subnets
- App runs in EC2 instance(s) in the public subnet
- RDS database
- Route53 DNS with health checks directs traffic to app
- Data stored in S3
This is good for a simple app, and is also a stepping stone when deploying more complex apps. The EC2 instance can be used for development or as a canary instance.
CloudFront for assets
Store app assets like JS and CSS in CloudFront for performance
CodePipeline for CI/CD
Whenever code changes, pull from git, build in CodeBuild, run tests and deploy automatically using CodeDeploy. Run tests against resources such as RDS or Redis.
Auto Scaling Group and Load Balancer
- App runs in an ASG in the private VPC subnet
- Blue/Green deployment
- SSL using Amazon Certificate Manager
- Spot instances to reduce cost
Worker ASG
Worker runs background tasks in an ASG, with its own build and deploy pipeline.
Multiple front end apps
- Load Balancer routes traffic between multiple front end apps
Shared S3 buckets
- Share data between S3 buckets
- Use signed URLs to handle protected user content
Static website
Build the public website using a static site generator in CodeBuild, deploying to CloudFront CDN. Use Lambda@Edge to rewrite URLs.
Elasticache
Add Elasticache Redis or Memcached for app caching.
Elasticsearch
Add Elasticsearch for the app.
DevOps
Add a DevOps instance to handle deployment and management tasks.
Bastion host
Add Bastion host to control access to servers in the private subnet. Or use with AWS SSM Sessions.
Prometheus metrics
Add Prometheus for application metrics and monitoring
SES
Use SES for email.
How it works
It uses Terraform to create the infrastructure, Ansible and Packer to set up instances and AMIs. It uses AWS CodePipeline/CodeBuild/CodeDeploy to build and deploy code, running the app components in one or more autoscaling groups running EC2 instances.
The base of the system is Terraform and Terragrunt. Common Terraform modules can be enabled according to the specific application requirements. Similarly, it uses common Ansible playbooks which can be modified for specific applications. If an app needs something special, we can easily add a custom module for it.
We use the following terminology:
-
Apps are under an
org, or organization, e.g. a company.org_uniqueis a globally unique identifier, used to name e.g. S3 buckets -
An
envis an environment, e.g. dev, stage, or prod. Each gets its own AWS account -
An
appis a single shared set of data, potentially accessed by multiple front end interfaces and back end workers. Each app gets it's own VPC. A separate VPC, generally one per environment, handles logging and monitoring using ELK and Prometheus -
A
compis an application component
We have three standard types of components: web app, worker and cron.
Web apps process external client requests. Simple apps consist of only a single web app, but complex apps may have more, e.g. an API server, admin interface or instance per customer.
Workers handle asynchronous background processing driven by a job queue such as Sidekiq, SQS or a Kafka stream. They make the front end more responsive by offloading long running tasks. The number of worker instances in the ASG depends on the load.
Cron servers handle timed batch workloads, e.g. periodic jobs. From a provisioning perspective, there is not much difference between a worker and a cron instance, except that cron instances are expected to always be running so that they can schedule jobs. Generally speaking, we prefer to move periodic tasks to Lambda functions where possible.
We normally run application components in an auto scaling group, allowing them to start and stop according to load. This also provides high availability, as the ASG will start instances in a different availability zone if they die. This makes it useful even if we normally only have one instance running.
Running in an ASG requires that instances start from a "template" image AMI and be stateless, storing their data in S3 or RDS. We can also run components in standalone EC2 instances, useful for development and earlier in the process of migrating the app to the cloud.
We can also deploy the app to containers via ECS as part of the same system. Everything is tied together with a common ALB, so it's just a question of routing traffic.
When possible, we utilize managed AWS services such as RDS, ElastiCache, and Elasticsearch. When managed services lack functionality, are immature or are expensive at high load, we can run our own.
The system makes use of CloudFront to host application assets as well as static content websites or "JAM stack" apps using tools like Gatsby.
We deploy the application using AWS CodeDeploy using a blue/green deployment strategy. The CodeDeploy releases can be built using CodePipeline or a DevOps EC2 instance.
By default we use Route53 for DNS and ACM for certificates, though it can work with external DNS, certs and other CDNs like CloudFlare.
Terraform structure
Using Terragrunt, we separate the configuration into common modules, app configuration and environment-specific variables.
Under the terraform directory is the modules directory and a directory for
each app, e.g. foo:
terraform
modules
foo
bar
For many apps, the recommended Terragrunt structure in Keep your Terraform code DRY and example works fine. It uses a directory hierarchy like:
aws-account
env
region
resources
e.g.
dev
stage
us-east-1
asg
In this case, we may have multiple prod environments in different regions, each potentially with its own AWS account. We use a flatter structure combined with environment vars which determine which config vars to load.
Under the app directory are:
terragrunt.hcl
common.yml
dev.yml
prod.yml
dev
prod
terragrunt.hcl is the top level config file. It loads configuration from YAML
files based on the environment, starting with common settings in common.yml
and overriding them based on the environment, e.g. dev.yml.
Configure common.yml to name the app you are building, e.g. org, app
and set the region it will run in.
Next configure the resources for the environment, e.g. dev. Each resource
has a directory which defines its name and a terragrunt.hcl which sets
dependencies and variables.
Dirs for each environment define which modules will be used. For example, this defines a single web app ASG behind a public load balancer, SSL cert, Route53 domain, RDS database, CodePipeline building in a custom container image, deploying with CodeDeploy, using KMS encryption keys:
acm-public
asg-app
codedeploy-app
codedeploy-deployment-app-asg
codepipeline-app
ecr-build-app
iam-codepipeline
iam-codepipeline-app
iam-instance-profile-app
iam-s3-request-logs
kms
launch-template-app
lb-public
rds-app
route53-delegation-set
route53-public
route53-public-www
s3-app
s3-codepipeline-app
s3-request-logs
sg-app-private
sg-db
sg-lb-public
sns-codedeploy-app
target-group-default
vpc
Modules are named by the AWS component plus a component-name suffix, e.g. asg-api
for an autoscaling group for a web component handling API requests. Each
component is a directory and a Terragrunt config file specifying the module and
any necessary variables. For example:
terraform {
source = "${get_terragrunt_dir()}/../../../modules//asg"
}
dependency "vpc" {
config_path = "../vpc"
}
dependency "lt" {
config_path = "../launch-template-api"
}
dependency "tg" {
config_path = "../target-group-api"
}
include {
path = find_in_parent_folders()
}
inputs = {
comp = "api"
min_size = 1
max_size = 3
desired_capacity = 1
wait_for_capacity_timeout = "2m"
wait_for_elb_capacity = 1
health_check_grace_period = 30
health_check_type = "ELB"
target_group_arns = [dependency.tg.outputs.arn]
subnets = dependency.vpc.outputs.subnets["private"]
launch_template_id = dependency.lt.outputs.launch_template_id
launch_template_version = "$Latest" # $Latest, or $Default
spot_max_price = ""
on_demand_base_capacity = 0
on_demand_percentage_above_base_capacity = 0
override_instance_types = ["t3a.nano", "t3.nano"]
}
The source identifies the Terraform code, in this case asg-app, and the
dependencies. The second part sets variables, e.g. AMI and instance type, ASG
size and health check parameters.
Outputs of one module are stored in the state, and we can then use them as inputs for other modules. The system is flexible, using separate modules identified by name and path. This makes it straightforward to define multiple front end or worker components or customize modules when necessary. This is a key advantage of Terraform over CloudFormation. When CloudFormation config gets large, it becomes hard to manage and extend. Terraform also supports multiple providers, not just AWS.
The configuration for dev is normally roughly the same as prod, but
with e.g. smaller instances. It's possible, however, to have different
structure as needed.
Ansible structure
Ansible is used to set up AMIs, perform tasks like creating db users, and generate config files in S3 buckets from templates. We may use the Ansible vault to store secrets or put them into SSM Parameter Store.
The structure generally follows the approach in "Setting Ansible variables based on the environment".
playbooks contains common and app-specific playbooks.
manage-users.yml
files
foo
app-ssm.yml
bastion.yml
bootstrap-db-mysql.yml
bootstrap-db-pg.yml
bootstrap-db-ssm.yml
config-app-https.yml
config-app.yml
devops.yml
packer-app.yml
files has common files used by the playbooks, e.g. ssh public keys used by manage-users.yml.
vars contains configuration for each env. Most configuration is done here,
not in the inventory, due to the need to manage multiple environments.
foo
dev
app-https.yml
app-secrets.yml
app.yml
bastion.yml
common.yml
db-app.yml
devops.yml
Following is an example playbook used to provision an AMI, playbooks/$APP/packer-$COMP.yml:
- name: Install base
hosts: '*'
become: true
vars:
app_name: foo
comp: app
tools_other_packages:
- chrony
# Parse cloud-init
- jq
# Sync config from S3
- awscli
vars_files:
- vars/{{ app_name }}/{{ env }}/common.yml
- vars/{{ app_name }}/{{ env }}/app.yml
- vars/{{ app_name }}/{{ env }}/ses.yml
- vars/{{ app_name }}/{{ env }}/ses.vault.yml
- vars/foo/{{ env }}/elixir-release.yml
roles:
- common-minimal
- tools-other
- cogini.users
- iptables
- iptables-http
- codedeploy-agent
- cronic
- postfix-sender
- mesaguy.prometheus
- postgres-client
- cogini.elixir-release
It loads its config using vars_files from the vars directory, then runs a
series of roles.
Packer structure
To actually build the AMI, we use Packer.
Makefile
README.md
builder
build.sh
build_centos.yml
build_ubuntu.yml
foo
dev
build_app.sh
build_cron.sh
build_worker.sh
set_env.sh
Set OS environment vars and run:
./${APP}/${ENV}/build_app.sh
This launches an EC2 instance and runs the playbooks/foo/packer-app.yml
Ansible playbook to configure it. The result is an AMI ID which you put into
e.g. the image_id var in terraform/foo/dev/launch-template-app/terragrunt.hcl.
Need help?
Need help deploying your complex app? Get in touch!