Breaking up the monolith: building, testing, and deploying microservices
By in Programming on Tue 02 January 2024
I recently worked with a large e-commerce company to "break up the monolith".
They have three main applications, a web front end in Elixir/Phoenix, a large Ruby on Rails application used for internal processing, and a large Absinthe GraphQL API that glues the pieces together and integrates with third party APIs.
The primary motivation for the project was to improve reliability by decoupling the back end application from the public website. With big applications, it's easy for a change in one component to break another unrelated component. Just upgrading a library can be dangerous, but is necessary to deal with security vulnerabilities.
Another goal was to make independent components that could be developed more quickly. Finally, they wanted to improve security by compartmentalizing access and making them easier to audit.
We ended up with a plan to extract relatively-large components into services such as "users", which handled user registration, login, and settings. We needed to be able to incrementally update the system the system while keeping compatibility and ability to roll back. We used federation to break up the GraphQL backend into separate services while keeping the same public API.
Some things that are "nice to have" in monolithic systems become critical with microservices, e.g.:
- Effective automated testing, including comprehensive tests which ensure that services can be updated without breaking clients
- Fast, easy, and reliable deployment
- Effective processes for development and QA that work with multiple components
- Observability to identify and debug problems which go across components
Some specific things we implemented:
- Testing against the deployed OS image, allowing OS updates to be tested against the code, particularly important when security issues are identified in base images
- Static code analysis tools and security scanners, improving quality
- Test results integrated into the pull request UI, providing actionable feedback to developers
- Supporting development and QA across multiple services in local or review environments
- Improved build performance through better caching and parallel execution, reducing cost through better efficiency and improving developer experience by reducing time spent waiting when deploying
Some challenges we faced included:
- Difficulty splitting up complex GraphQL schemas and untangling application dependencies
- Application configuration, particularly secret management
- Difficulty assigning code ownership
Show me the code!
The rest of this post gives details and motivation for the architecture at a high level. But first, here are some running examples that show how to do it:
- phoenix_container_example shows shows a CI/CD system based on containerized build and tests running in GitHub Actions, deploying to AWS using Terraform.
- absinthe_federation_example shows how to test federated GraphQL applications based on Apollo Router.
See below for a description of how the code works.
Testing is critical
Testing is the most important part of microservices, particularly in a situation where the monolith has become big enough that it's causing problems.
We need to have a hierarchy of tests, going unit tests that are quick to run but fake to integration tests that test the real running system:
- Unit tests with synthetic data embedded in the code or external files
- Unit tests with data from a database
- Unit tests for an external service with mocked APIs, i.e., not actually communicating with the service
- Unit tests for an external service (e.g., Salesforce or Algolia) communicating with the service in a test environment
- External tests with data from a database or external service in a test environment
- External tests that combine data from multiple services, i.e., GraphQL federation.
- Health checks
The core process is based on running automated tests in dev and CI, with optional manual testing by QA. We can confidently deploy code if we have good automated code coverage. We also need observability support to identify regressions in production and debug them. Additional deeper checks may be valuable after the code is released, e.g., load tests or security checks.
Unit tests are written in Elixir or Ruby their unit test frameworks. They start with synthetic data embedded in code or external files. Subsequent tests cover higher-level APIs that pull data from a database or communicate with an external service. We start by creating a mock version of the external service which returns test data. Some services provide a test sandbox or test mode for the production service, allowing us to perform integration testing against the real service. We may also be able to run services in containers for testing.
Here, external/integration tests use Postman/Newman. Postman is an interactive UI for creating and managing API tests, used by testers in development or QA environments. It includes a headless runner (Newman) for CI.
There is a trade-off between synthetic tests and integration tests. Synthetic tests run quickly and reliably but may end up not being accurate, as they are effectively only testing fake data and mocks. Integration tests exercise the full end-to-end functionality, e.g., talking to actual external services. They are more accurate but run slower and may be flaky when external services are unavailable.
Mocks and fake data
Mocks are functions that have the same interface as a library or service but return predefined data instead of calling the real service. They avoid dependencies on external services when running tests and improve test speed. Mock data may not reflect the actual behavior of the system, however. We may end up testing our mocks, not reality.
As we break up services, we need a solid test suite that validates the external API for each service, providing a contract for consumers. Whatever changes we make internally should not break other parts of the system. We can collect queries running on the current system and use them as a regression test to ensure that we are not breaking clients, even if they are somehow invalid. For example, after upgrading Absinthe GraphQL, it may start rejecting invalid queries that it accepted before.
While useful, the mocking process can result in code and configuration complexity. Where possible, we should avoid mocking in favor of using real data.
Using Tesla for the HTTP client library simplifies the mocking process. It includes a test “adapter” that removes the need to change the server URL at runtime, something that causes configuration problems.
Seed data is also needed to provide a stable base for external API tests. It provides a base of data that tests can expect to be there, e.g., users and products. Other data may be created during the tests, e.g., creating an order for a product.
A larger but more comprehensive database snapshot is also useful for dev and review environments. It is an anonymized subset of the production database, with enough realistic data to support testing. Larger databases can also be used for, e.g., overnight load testing in staging.
One performance trick is to snapshot the schema and test data as SQL, then build it into Postgres test container. This is much faster than running lots of little database migrations.
Static code analysis tools
Static analysis tools perform quality, consistency, and security checks on code. Manually written tests tend to exercise the normal execution code paths, while consistency tools find problems with less common code paths. Quality tools identify error-prone programming patterns, failure to handle error cases, security issues, and the like.
Examples for Elixir include:
- Credo (code quality)
- Dialyzer (type consistency checking)
- mix audit (security check for Elixir packages with known issues)
- Test coverage (checking what percentage of the code the tests exercise)
- Sobelow (web security for Phoenix, e.g., cross-site scripting, SQL injection)
- Trivy (vulnerability scanner for code and operating system). Other similar tools include Grype, Gitleaks, Snyk, GitHub Advanced Security, and SonarQube
- Styler is a plugin for the Elixir formatter that fixes problems identified by Credo instead of complaining.
The results of static code analysis need to be surfaced to developers so they can take action. Best is to integrate results into the developer’s editor, showing errors inline. Next best is running in CI.
Using a tool like Hound, we can integrate test results into the PR process as comments. This avoids the "wall of text" that nobody reads unless it actually breaks the build. Developers can first fix these issues, allowing reviewers to focus on high-level concerns.
Adding quality checks to an existing project can be challenging, as it results in hundreds of issues. It can be tough getting them through a traditional PR approval process. One solution is to snapshot the results and only break on new problems.
Testing in containers
Many CI systems don't test the actual running system. They run tests in a
generic Linux container, effectively just checking out the code and running
mix test the same as on a developer's machine.
Instead, we should run tests in an environment that matches the target system as closely as possible, allowing us to identify problems from library incompatibilities or misconfiguration. This lets us safely upgrade the base image, e.g., in response to security vulnerabilities, and test that the code works with it.
Security vulnerabilities represent a fundamentally different workflow from development. In the normal process, we start with a PR, run it through a test and review process, and then release it when it is ready. In the security process, we start with the production code/released container, then run security scans which identify newly-discovered vulnerabilities. Those trigger a process of upgrading libraries/OS releases and testing code against them. The review process for security issues needs to be able to run quickly and safely, mostly based on automated tests, as we are vulnerable to security problems until the update is in production.
Example CI build and test process on GitHub Actions
The GitHub Actions build process runs tests against containers, including unit tests, code quality checks, external API tests, and security scans.
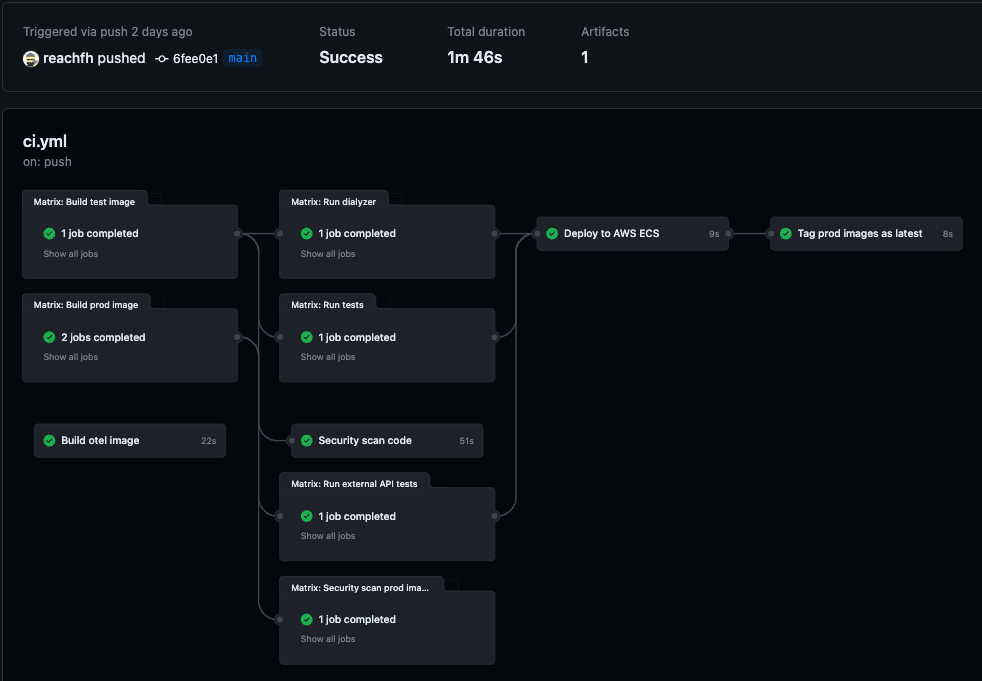
As part of CI, it builds two containers, test and prod. The test container has the source code and potentially other test tools. The prod image only has the minimal OS and application. The application is built using Erlang releases, which contain only the code needed for the production application, reducing size and attack surface.
The CI process first builds the two containers in parallel, then runs tests against them in parallel.
It uses a containerized version of the database which is initialized using migrations and seed data. Internal tests use a combination of ephemeral test data and persistent seed data in the database. It also includes containerized versions of other back end services such as Redis and Kafka.
External tests make calls using Newman against the service's public GraphQL API, returning results from persistent seed data in the database. These integration tests have full fidelity to the ultimate environment. In order to implement this, we need to write the API tests (or extract them from unit tests) and build seed data to support them.
For a microservices system, we can run the external tests against multiple containers at once. The absinthe_federation_example tests bring up containers for Apollo GraphQL Router, the container for the newly-updated code, as well as release containers for other services that are part of the same user scenario. We then run tests using Newman against the Apollo Router container, which routes requests to one or more service containers. Similarly, we can run tests for a website that calls a back-end API. Or we can run a headless browser testing framework to test the front end.
When we run CI for a service, we test that new code for the service works well in isolation and in combination with other services. Once these tests pass, we create a new production image for the service. We push this image to the GitHub Container Registry (GHCR) as part of testing. In the final step, we push to a production AWS ECR repository. GHCR runs internally to GitHub, improving build performance. As a result, tests always have access to the production container image for each released service as well as the new release of the code for the current service. This allows us to run integration tests against all the services as a group.
All of the above tests can run in parallel, so the total build and test time is fast (about two minutes). Tests can also be parallelized by partitioning the test run if they take a lot of time.
Security scanning
The build process runs security scanners in three phases:
-
During testing, run unit tests, code quality tools, and security checks on the code.
These run on the test image, which includes a checkout of the app source code. We run tools such as Trivy to check for security problems on our code and dependencies. It reads JavaScript package files to identify dependencies with known vulnerabilities.
-
After building the prod container, run security checks on it.
This container has only the minimum needed to run the app and has minimized versions of final JavaScript code. It runs security checks again, this time checking the OS image for known vulnerabilities and configuration problems, e.g., world-writable directories.
-
After release, periodically run security checks to identify newly identified vulnerabilities.
Code-level security problems should break the build. It’s probably also the best location to deal with vulnerable JavaScript libraries. These kinds of issues could be found after release, as well, so it probably makes sense to run most of this in the periodic job as well.
Here, the scan outputs results in SARIF formats. It then uploads the results to GitHub, where they appear in the Security tab. This requires a GitHub Advanced Security license, though it is free for public open source. It is straightforward to use a similar mechanism to run any other security scanning tools. Using command line tools avoids pricing models that charge per developer.
Health checks
External API tests and scenario-based production health checks are quite similar. In production, instead of simply checking for success or failure, we can run a request against the production database and ensure that we get back the data that we expect.
Developer experience
Splitting up services can improve the experience for developers, as they can work on a smaller codebase with faster, more reliable tests and shorter development cycles. They can make changes without worrying that they will break another part of the code that they are not involved with. CI tests and static code analysis make deployments more reliable.
Developers need a quick feedback loop when developing code, so they need quick tests that fail fast. We then run additional tests in CI that take more time or rely on external services. These services may be unreliable and block deployment, as we need to retry tests until they succeed.
Fast builds also reduce the impact of outages. When your tests take 30 minutes to run, the duration of outages with code fixes are all multiples of 30 minutes.
In this application, the Ruby on Rails tests took 4 hours to run on a developer's machine, so everyone relied on CI. With parallel execution, it would take about 25 minutes to run there. Flaky tests were a big problem. They would randomly fail, then succeed on the next run (or the next). We spent effort to instrument the builds to identify flaky tests and prioritize fixing them, improving developer experience and avoiding wasted time.
The downside with microservices is that developers need more dependencies up and running in order to work on a piece of code. They might need a dozen services running to be able to test their changes. Containerized development helps with that. The containerized build process means that standard, pre-built images for each service are available in GitHub, so developers do not need to build images locally.
The biggest complaint about containerized development is performance. Some recent improvements to disk I/O to Docker help. It’s should be possible to run a local database and develop code locally while talking to containerized versions of other services.
Using local Kubernetes for development makes it more consistent with the production environment. Another option is to give each developer their own equivalent environment in the cloud. They can then use one or more services locally while connecting back to the development environment, e.g., with https://www.telepresence.io.